声笔简拼极其简单、高效,没有什么学习门槛,可以用一句话概括它的内容:用v表示零声母,用aeuio分别表示折、横、撇、竖、点五种笔画,采用首字母简拼加笔画编码。新用户几分钟就可以学会,几小时就可以熟练掌握,稍加强化输入速度就可以上百。
1 一个例子
例子: 中文输入法是中文使用者的基础工具。
方法1: 中文zwoe 输入法srfo 是s_ 中文zwo 使用者syze 的d_ 基础jc_ 工具。gji.
方法2: 中文输入法zwsrF 是s_ 中文使用者zwsyZ 的d_ 基础工具。jcgj.
在例子中,方法1是分词颗粒度比较细的打法,而方法2是分词颗粒度比较粗的打法,下面会给出详细的操作过程。方法2是建立在已经使用过方法1的前提下的,类似于实际输入过程中,上文已经出现过类似的句子,所以可以通过更粗的分词来进一步压缩编码,从而节约用键。因为简拼是动态调频的,用户的结果不一定会一模一样,但是并不妨碍对操作方法的理解。
使用方法1时,首先输入「中文」两字的声母zw,观察首选不是「中文」(若能记住二简词,是不必观察的),于是追加「文」的首笔点o,还是未命中,再追加「文」的次笔横e,命中了。这时,不必空格上屏,而是接着输入「输入法」中第一个字「输」的声母s,「中文」会被顶上屏幕,接着输入「入法」的声母rf和「法」的首笔点o,首选就是「输入法」了。为什么输入三个声母后不进行观察呢?因为在默认模式下,三个声母对应的肯定是二简词和一简字的组合「虽然发」,肯定不是「输入法」,所以只需要在追加末字的首笔再观察提示。接下来,键入「是」的声母s,将「输入法」顶上屏幕,用空格键上屏一简字「是」,因为一简字是不能顶屏的。接着,输入zwo,即开始观察提示,因为简拼的二字词是三码起开始调频的,发现「中文」已经在首选。于是,键入syze,将「中文」顶上屏幕,发现首选就是所需的「使用者」。再键入d,将「使用者」顶上屏幕,并用空格上屏「的」字。然后,输入jc,发现「基础」已经是首选,二简词不能顶屏,所以用空格上屏。最后,键入gj,二简词是「国家」,于是追加「具」的首笔竖i,命中了「工具」,直接键入句号顶屏,完成整句话的输入,包括句号本身。
使用方法2时,「中文输入法」的末字声母要用大写,否则小写的f会将前四个声母对应的词「中文输入」顶上屏幕。实际上,大于五字的声母都要用大写来输入,这是编码规则。因为zwsrF对应的首选正好是「中文输入法」,所以接着键入s,就将其顶上屏幕了,然后再用空格上屏「是」字。类似地,输入zwsyZ,正好命中了「中文使用者」,键入d将其顶上屏幕,用空格上屏「的」字。最后,键入jcgj,发现首选没有命中,于是追加末字首笔i,首选变成了「基础工具」,直接句号顶屏,完成全句输入。
2 操作详解
2.1 分词
声笔简拼实际上是一个基于整句算法的字词型输入方案。所以,分词是输入过程中非常关键的一步。对于习惯传统拼音输入法且没有良好分词习惯的人来说,分词可能是一个难点。但是,分词对于中文输入来说,再怎么强调也不为过,即使采用传统拼音输入法也是如此,否则可能会严重影响拼音输入法的音字转换准确性,或者导致回改成本居高不下,甚至出现错别字,影响输入的质量。
中文在书写上并没有显示出词与词之间的界线,但是在语文教学中和我们平常说话时中,汉语词的概念还是体现得比较充分的。在语言学上,词被定义为最小的能独立运用的语言单位,也包括能独立运用的单字。但是,在输入法中,词的定义并没有这么严格,凡是被当作一个单位来进行编码和转换的一串字就是一个词。所以,输入法中的词可能是单字、单词、短语甚至短句,但是一般不包含非汉字符号。
根据不同的应用场景,分词的颗粒度可细可粗,以便在低打空率和高压缩率之间取得最佳的平衡。若以单字为单位来输入,则肯定不会打空,打空率为零,而且不需要分词,分词成本也为零。然而,单字用键多,重码也多,输入效率太低。现代汉语是以二字词为主导的,三字词和多字词也日益增多。声笔简拼的单字输入是其弱项,更应该尽量以词为单位来进行输入,而且分词的颗粒度在可控的打空率下应当尽量地以较粗为好,因为声笔简拼具有自动造词的能力,打空也是一次性的,组词成功后,就可以当成正常词组来使用了。
2.2 编码
编码是声笔简拼输入过程中最关键和最复杂的一步,而编码是遵循一定格式的。为了避免歧义和便于记忆,我们用下列类似正则表达式的精简方式来描述字词的输入格式。
通式:
s(b*4)s*3S*b*2
以上是最一般的通用表达式,其中s = [qwrtsdfgzxcvbyphjklnm]表示声母,b = [aeuio]表示笔画,*表示零个或者多个,数字表示最大个数,括号表示补码,其位置实际上在最后。用文字来表达就是:声笔简拼 = 超级简拼 + 末字两笔 + 首字两笔。
上面的通式非常精简,但是也过于抽象,下面按照字词的类型对表达式进行分解,以期更加具体和准确。
单字:
sb*4二字词:
s(b*4)sb*2三字词:
s(b*4)ssb*2四字词:
s(b*4)sssb*2五字词:
s(b*4)sssSb*2六字词:
s(b*4)sssSSb*2……
2.2.1 动态、静态与变换
普及型输入方案的码位一般都是动态的,其上的字词会随着使用而发生变化,不断适应用户的使用习惯,以使得平均码长最短,从而提高输入效率。在传统拼音输入法中,所有编码都是动态的,这是一种极端的做法。
当调频走向极端的时候,会造成严重的高频震荡问题。高频震荡是指短码位上的字词频繁发生变化,导致与人的条件反射或肌肉记忆发生剧烈冲突,需要随时监控候选字词,使得人机交互大大增加,不得不减慢击键速度,而且输入错误也因为习惯动作而大大增加。
一、二简码位的使用频率极高,在动态调频的情况下,它们发生高频震荡现象也就极为频繁。所以,声笔简拼的s和sb是静态编码,其上的单字是固定的,不变的,分别称为一简字和二简字。同样的,ss是静态编码,其上的二字词也是固定的,不变的,称为二简词。sss上安排的是二简词和一简字的组合,而不是一般的词组。这种安排有助于用户在使用过程中对它们形成条件反射,以期大幅度地减少人机交互,提高平均击键速度和打字效率。
变换操作用于输入一简字、二简词之间的组合,也属于静态编码的范畴,熟悉后可以盲打。
两个一简字的组合:
ss; => s_s_一简字与二简词的组合:
sss; => s_ss_三个一简字的组合:
sss' => s_s_s_两个二简词的组合:
ssss' => ss_ss_
2.2.2 主码、辅码与补码
字词编码表达式中的s称为主码,b称为辅码,括号中的b特称为补码。补码实际上是输入词组时,回头补充的首字辅码。追加辅码的操作,不管是否为补码,都称为加码。为什么要颠三倒四的回头补码呢?这个看似笨拙的做法却正是声笔简拼在设计上的精妙之处。
为了尽量缩短码长,就需要优先使用超级简拼,但是超级简拼的空间非常有限。在声笔简拼中,单字的超级简拼空间只有21个,二字词的超级简拼空间也只有441个,面对数万个单字和数十万个二字词,势必会产生大量的重码。处理重码最简单的办法就是列出来让用户选择,然而这是极其低效的方法。高效的办法是加码。加什么样的码呢?对于传统拼音输入法如搜狗拼音来说,就是加末字的韵母,而对于声笔简拼来说就是加末字的笔画。当然,就单字来说,末字就是单字本身。
搜狗拼音如果强制使用超级简拼的话,因为没有快捷的补码手段,输入时会遇到巨大的困难。繁琐的回改将使得超级简拼节约的用键变得无足轻重,甚至得不偿失。所以,在搜狗拼音中,为了保险起见,一般是先用全拼输入一次以后,再使用超级简拼,不但降低了输入效率,而且还失去了输入的一致性。另外,由于a e o可以出现在超级简拼中,而n g可以被解释为韵母的一部分,因此会导致超级简拼的解释出现歧义,降低了音字转换的准确性。
在声笔简拼中使用超级简拼则不会有任何问题。由于主码和辅码使用的编码字符集是不相交的,所以在使用超级简拼时,绝对不可能发生解释上的歧义,在补码时一般也不需要手动定位,可以大大简化回改操作,从而加速输入过程。
所谓回头补码,就是在末字输入了三码时,若继续输入aeuio则被当作对首字的补码,可以补充首字的第二至五码。而且,在补充完第五码时,就只会检索与首字同码的单字了,因为一般来说,词组的重码这时都已经查找完,需要开始构造新词了。在少数情况下,可能你并不希望这样继续补码,那么就可以通过手动定位来进行干预,也可以通过翻页查找继续检索后面的候选项。
当然,回头补码也是有代价的。特别是在使用的初期,会有颠三倒四的感觉,但是经过一段时间的训练和熟悉,完全可以变得非常熟练,最终达到无需思考的地步。实际上,定位修改也是一种回头补码,只不过省略定位环节后,回头补码的过程加速了,加上没有视觉上的提示,才显得比较困难。
2.3 反查
在使用简拼时,特别是在学习简拼之初,有时会遇到不会打的字。怎么办呢?程序提供了丰富的反查手段,可以通过笔画和拼音来反查编码,还可以采用字海两分来反查和输入非 GBK 汉字。另外,还通过反查提供了临时拼音输入法。
2.3.1 拼音反查
在知道拼音而不知道字形时用 a 引导拼音反查,注意零声母要用 v 充当。
例如,要反查「防」字的编码,就在输入 a之后再输入它的拼音 fang,所以实际的输入为 afang,结果如下图所示。反查出「防」字的编码为 faioe。如果是多音字,那么就会有多个编码,如图中的「房」字就有 foaeu 和 poaeu 两个编码。

对于零声母字,如「案」字,在反查时除了用 a 引导还需要在正常拼音的前面加 v,因为 an 是零声母音,所以实际的输入为 avan。在图中提示出的案vooaa,表示「案」字的编码为 vooaa。

2.3.2 笔画反查
在完全不知道读音的时候,直接用 aeuio 按顺序输入笔画进行反查,无需引导。
在下面的笔画反查的例子中,不用引导而直接输入 uuao 后,出现了以这四个笔画开头的字。第一项是反fuuao,表示「反」字的编码为 fuuao。第二项为般buuao buuao puuao,说明「般」是个多音字,前两个编码相同是因为有两个音的韵母是不一样的,而简拼没有使用韵母,所以体现不出区别。

2.3.3 两分反查
通过 i 引导的拼音还支持用字海两分法来进行反查, 支持查找八万多汉字,一般用于反查难读而易于两分的字或者输入 GBK 以外的字。GBK 以外的字,声笔简码不提供正常编码,不能按正常方式输入,只能在两分查找到后选择输入。引导字母i可以理解为英文inquire(询问)的首字母,以便记忆。
下面是字海两分法查找的例子。第一个例子是反查「龖」字的编码,在输入到第二部分拼音的第一码时就出来了。第二个例子是通过输入「尸」和「水」的拼音来反查「尿」的编码,输入了两部分完整的拼音。
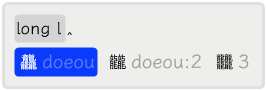

对于非 GBK 字集里的「㕛」字,它是没有编码的,只能用两分法来输入,如下所示。
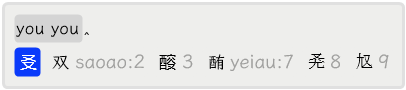
2.3.4 临时拼音
在一时半会想不起某个词中某个字的笔画,而这个字因为不常见又不方便用单字进行反查时,可以用 a 引导临时拼音来变相地输入词组或者查到该字的写法。
例如,「饕餮」可以用 ataotie 来查找和输入,而「耄耋」可以用 amaodie 来查找和输入。注意,用于引导的字母a是不会显示的。


2.4 定位
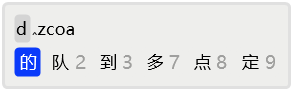
上节所讲的回头补码实际上是一种自动定位机制。但是,这种自动定位需要在末字输入了三码时才能发挥作用。有时候,并不希望等到末字输入三码后才补码,而是想在末字输入一码后就补码。这时,就需要采用手动定位了。手动定位使用数字1和0,其中1定位到首字编码的末尾,而0定位到末字编码的末尾,N次使用1则顺序定位到第N字编码的末尾。在字数多于2时,可以用单引号直接定位到第二字的编码之后。
比如,在输入「多字词」时,如果输入了dzcoa后,预判系统中没有该词,则可以按1快速定位到d后,用7选择「多」,再用2选择「字词」,就完成了「多字词」的输入。

2.5 调频
补码解决了快速筛选重码的问题,但是却带来了很多字词的码长太长的问题。在声笔简拼中,单字和二字词的短码空间很小,码长问题显得特别突出。系统默认的字频和词频,对于一些普通常用字词,可能适合大多数用户。
然而,每个用户都肯定会有自己的一套字词使用习惯,希望自己用得多的字词具有更短的码长。实时动态调频就可以做到这一点。比如,对于学习和研究声笔输入法的人来说,「声笔」和「声笔简拼」都是高频词,而对于其他人来是它们可能就是低频词,甚至根本就不是词。通过调频,「声笔」只需要三键就可以输入,而「声笔简拼」只要四键就可以输入。在频繁使用的情况下,节约的用键是可观的。
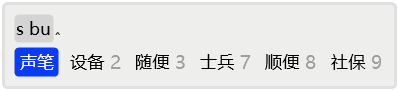

2.6 顶功
调频虽然可以调教字词频率,让用户经常使用的字词码长缩短,但是如果每个字词都需要像传统拼音那样用空格上屏的话,也是一件非常烦人的事情。特别是对于那些习惯了整句输入而很少用空格的人,更是难以忍受频繁的空格键击打。
能否在尽量缩短码长的同时又尽量省略空格键呢?声笔的秘密武器——顶功,给出了肯定的答案。在声笔简拼中,可以做到单字两码起顶、二字词三码起顶、三四字词四码起顶,五字及以上词通过大写第五及以后字的声母也可以实现首字母顶功。
例如,在输入dei后,如果首选是「都」字,那么在有后续输入的情况下,是不必用空格上屏的,只需要输入后续字词的首码,「都」就会被顶上屏幕。

再如,输入plo后,如果首选是「 频率」,那么在连续输入时,也是不需要空格上屏的。
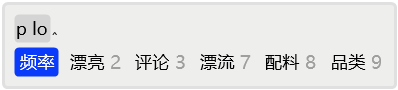
2.7 选重
在使用声笔简拼进行输入时,除了静态的一、二简字词及其组合外,一般会尽量通过加码,将所需字词提前到首选,以便减少盯屏区域,并利用顶功上屏来节约空格。
但是,选重操作在有些时候仍然是不可避免的。在输入非常用字的时候,即使追加了四个笔画,所需的字可能仍然未被提前到首选,需要进行重码选择。在不太确定第三、四笔是什么时,也可能想马上进行重码选择。在输入词组时,可能因为对后面的笔画不熟悉,在补充首字前两笔后就想通过选择来上屏。在个别情况下,可能还需要翻页操作。
为了使选重操作变得快捷,声笔简拼使用了23789作为选重键,而不是传统拼音输入法的12345。而翻页操作在声笔简拼中是用得非常少的,所以采用了Tab和Shift+Tab来翻页。
例如,输入「戴」字时在输入了全部五码后,提示如下,用7就可以选择「戴」上屏了。

再如,输入「校」字时在输入了全部五码后,首页没有,用Tab翻页一次后,出现在了次选,可以用2选择上屏。


2.8 造词
声笔简拼拥有一个巨型词库,收录了雾凇拼音的200万词组,而且还支持rime的octagram语言模型,已经具有大厂拼音输入法云词库的效果了。但是,每个用户都或多或少地需要输入一些系统未收录的词组。一般来说,用户会按自己的习惯来进行分词输入,在输入的时候并不知道系统中是否已经收录了待输入的词组。在遇到未收录的词组时,就会发生无法命中而打空的情况。
打空以后,声笔简拼可以无缝地进行造词。办法是,先顺序补末字两码,然后补首字的编码,在补码的过程中观察是否出现所需的词组。当候选中出现比所需词组更短的词时,说明系统没有所需词组。此时,若出现构成所需词组前缀的字词,则选中进行组词。在输入完首字的五码后,会自动进入单字模式,让用户选择与首字重码的字。如果首选字正是所需的字,则可继续补次字的编码,系统会自动定位。在必要的时候,也可以手动定位进行干预,如果这样更高效的话。重复以上过程,直至造好所需词组。
如果已知某个五字及以上的长词在系统中没有而需要新造,那么采用输入首码后按Shift+Tab(手机是上滑Tab)进入缓冲模式来造词是最好的,这时只需要拆开后输入一遍这个长词即可,而不必先输入所有的声母再回头补码。
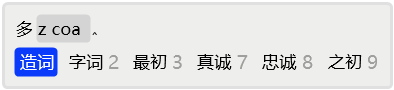
例如,若用户想输入「简词」,但是按正常输入并补码后,发现没有命中,而且从次选起都是单字了,说明系统中没有该词。
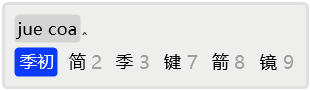
于是,用2选择「简」上屏。
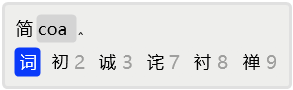
接着,发现首选就是需要的「词」字。
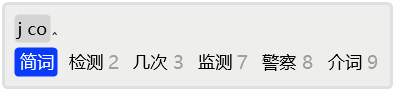
这时,可以空格上屏来完成造词。但是,如果还有后续字词想输入的话,可以直接输入后续字词的首码,将「词」字顶上屏幕,而无需按空格。
3 数选固定
除了一、二简字词外,声笔简拼还有大量固定的数选字词,包括210个声数字、1050个声笔数字和4410个声声数词,它们有助于提高声笔简拼的可盲打性,从而提高输入效率。每种数选字词均等分为有理的和无理的两组,默认情况下只提示有理组,可以设置为同时提示无理组,以下示例是设置为同时提示无理组的情况。有理组用23789代表折横撇竖捺,而无理组用’456和分号或者制表符进行选择,与笔画无关。
例如,在输入z后,如果直接输入’456;将顺序选择「真 之 作 主 再」五个字。

再如,输入ze后的情况如下,选择方法与上例相同,输入’456;将顺序选择「指 直 政 至 指」五个字。

又如,在输入zy后,如果直接输入’456或者Tab将顺序选择「怎样 重要 只要 主要 终于」五个词。

4 自定词典
声笔简拼的所有固定字词,包括一简字、声笔字、声声词等,以及所有固定的数选字词,都是可以修改定制的,它们位于sbjz.fixed.txt文件中。您修改保存后,重新部署一下就可以生效。