1 字速
对许多人来说,字速(打字速度)是个谜。这里的谜有三层意思:迷信、迷惑、迷失!迷信者盲目崇拜打字飞快的高手,希望有朝一日也取得同样的成就。迷惑者觉得有些人演示的速度太离谱、不可信,但又不知道是为什么。迷失者对自己感到失望,怀疑自己的能力,甚至觉得自己是个笨蛋,为什么我同排行榜上的打字高手差距那么大?
这个迷怎么破?让我慢慢道来。首先,我们要弄清打字速度究竟是什么。怎么定义打字速度呢?打字速度s的计算公式如下:
s = r ÷ l,
其中,s是指每分钟输入的字数,即打字速度,简称为字速,单位为字/分;r是指每分钟的击键次数,称为键速,单位为键/分;l是指平均每个字的用键数,包括空格、选择键、翻页键等,称为码长,单位为键。
一般的打字练习软件在计算时字数时,不仅包括汉字,还包括了标点符号,甚至包括了英文字母和数字等,这会造成字速的失真,因为非汉字字符常常只需要一键就能输入了,导致码长被非真实地缩短。
从字速的计算公式可以看出,打字速度取决于键速和码长两个因素。键速在码圈内通常又叫做击键。在码长一定的情况下,影响打字速度的决定性因素就是击键。在击键一定的情况下,决定打字速度的因素就是码长。然而,键速和码长都受很多因素的影响,情况相当复杂,将在接下来的两节详细论述。
然而,键速和码长都是统计平均值,是根据一定时间t内输入的总字数c和总用键数n计算出来的:
r = n ÷ t
l = n ÷ c
打字速度也可以按下列公式直接根据实测的总字数和总时间计算出来:
s = c ÷ t
2 键速
在中文输入时的键速会受很多因素的影响,绝不是单纯的一个击键动作。花费更多时间的,往往是击键之前的一系列活动。看打时的预读和想打时的思考,字词的编码过程,提示选项的查看,这些常常会成为影响键速的关键因素。
编码方式和码元集大小也会影响键速。编码尽量采用易于击打的组合,码元集尽量小,都有利于加快击键,有利于提高打字速度,但却一般会增加码长,这又会降低打字速度。偏面强调一方面都是不行的,如何平衡两者才是最关键的。
中文输入过程所花费的时间等于获取时间、编码时间、击打时间、选择时间、回改时间和处理时间之和。获取时间在看打时就是预读时间,在听打时则是听取时间,而在想打时就是思考时间。现代设备,不论是电脑还是手机,其处理时间都是非常短的,在人操作的同时进行的,一般可以忽略不计,只有在发生明显延迟的时候人才会感觉到。不同的人使用不同的输入法在不同的熟练程度时,花在不同操作上的时间是不同的。
对于最常见的拼音输入法来说,如果以句子为单位来输入,那么其获取时间和编码时间都短,击打时间因为码长较长是比较长的,选择时间因为不确定性而比较长,在发现输入和转换错误时的回改时间就很长了,总的时间花费有赖于转换的准确性,这是导致拼音整句输入速度不稳定和竞速成绩不理想的根本原因。如果以字词为单位来输入,那么其获取和编码时间都会增加,击打时间因为可以采用简拼而得到缩短,选择时间和回改时间因为观察的内容少而得到缩短,输入速度的稳定性也会增加。由于拼音的重码非常多,单字输入的效果非常差,所以基本上没有人会按单字方式来输入,只有在改错时迫不得已才这么做。
对于五笔字型来说,如果以句子来输入,其效果是非常差的,完全是避其长而用其短,所以基本上都是以字词为单位来输入,而有的单字派则以字为单位来输入。如果以字词为单位,那么其获取时间和编码时间都比较长,击打时间因为码长较短而比较短,选择时间和回改时间因为重码较多和可能打空而较长。如果以字为单位来输入,那么其获取时间和编码时间都比较短,击打时间因为平均码长增加而加长,选择时间和回改时间因为重码少和没有打空问题而变短。
3 码长
码长分为理论码长和实际码长。理论码长是根据文字的统计特性直接计算出来的,与具体输入方案没有任何关系,但是可以做为一个最方便和最合理的比较基础和实现上的追求目标,可以说是非常重要的数据。而实际码长则与具体输入方案密切相关,是衡量其效率最重要的指标,当然前提是使用的码元集一样,否则就失去了比较的基础。如果要对码元集大小不同的输入方案进行比较,就需要先将它们转换为相同的码元集大小,通常是转换为二进制最方便,因为理论值通常就是以二进制的形式来呈现的。折算方法很简单,将码长乘以一个系数即可,这个系数是log|K|,其中|K|为码元集的大小,log是以2为底的。
3.1 理论码长
根据信息论,文字是一种平稳离散信源,因此文字的信息熵是可以计算出来的。这个熵实际上就是以二进制计算的文字中每个字符的平均码长,即理论码长。对于中文编码输入来说,中文的熵一般是以汉字的来近似的,因为非汉字字符一般用不着进行编码,而且汉字在中文中占居了绝大多数。故而,中文熵通常又称为汉字熵。
讨论中文输入涉及到几个重要的熵有零阶熵、字熵、词熵、句熵和极限熵。零阶熵和字熵都是以中文字符为单位来计算的,不考虑任何字符与字符之间的关系,其中零阶熵不考虑字频,而字熵是要考虑字频的。词熵、句熵和极限熵则分别以词、句和无限长的序列来计算。这些熵考虑的字符间关系的范围是不同的,依次增大,导致熵依次减小。
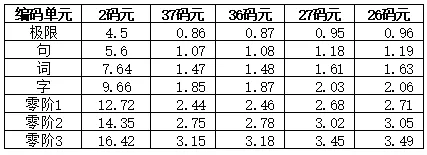
在上表中极限是指编码单元为无穷长的中文字符序列;零阶1、零阶2和零阶3分别指以GB2312-80的6763字符、GBK的20902字符和GB18030-2022的87887字符为准;2码元、37码元、36码元、27码元和26码元可分别看成是2进制、37进制、27进制和26进制。
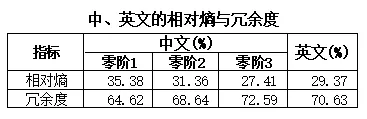
极限熵和零阶熵的比值称为相对熵,而1减去相对熵就是冗余度。相对熵反映的是有效信息的比例,而冗余度反映的是可被压缩的程度,它的值就是1-相对熵。
在上表中设中文的极限熵为4.5;零阶1、零阶2和零阶3分别指以GB2312-80的6763字符、GBK的20902字符和GB18030-2022的87887字符为准;设英文的极限熵为1.4比特,而英文字母包括空格在内为27个。
3.2 实际码长
速度s的计算公式也可以直接来自统计结果:
s = c ÷ t
单个样本甚至短期内的实测结果都不一定是准确的,往往与目标总体之间存在或大或小的偏差。更有人有意无意地利用这种偏差来夸大或者贬低某个人或者某个输入方案的效果,采用极端情况下的演示效果来以偏概全,所以造成了众说纷纭甚至相互矛盾的乱象,让初学者无所适从,不知道谁说的正确。
从信息论的角度来讲,有三个重要的因素:输入文本(信源)、输入方案(编码)和输入设备(信道)。信源的熵(熵率)决定了可被压缩的极限,而编码决定了实际的信源压缩程度,信道则代表用户操作设备(键盘)的能力,决定了传输效率。