存在的问题
在8.00的飞码(X)和快码(X)中,sbb和sbbb只是简单地放了声笔字,实际上几乎没投入使用,非常浪费。特别是在新增的飞码X和快码X中,因为没有sbbs型的二字词,sbb是只需要三键的短码空间,不好好利用的话,实在可惜。同时,飞码(X)中有少量spb短码空间是空闲的,而在快码(X)中存在着不少的sy和大量的syb短码空闲空间。
RIME版飞码(X)和快码(X)面临的另一个问题是,105个sb型简码字没有原生版那样的提示,初学者必须死记。
短码空间的利用
飞码(X)
首先,利用spb空闲空间。从声笔简码的二字词中抽出高频的填入该空间,脚本如下。
select zici = rtrim(zici), bianma = left(bianma,3), chupin = case chupin when -1 then 0 else chupin end from sbjerz
where changdu = 3 and left(bianma,3) not in (
select bianma = left(a.bianma,3)
from spdanz a
right join sbjerz b on left(a.bianma,3) = left(b.bianma,3)
where a.changdu = 3 and b.changdu = 3)
order by chupin desc一共抽取了67个ssb型的二字词,罗列其中的前10条如下。
那个 ngu 169294
儿子 vza 61768
任务 rwu 57310
不好 bha 54085
放心 fxo 46543
若是 rsi 39942
空中 kzi 25849
吩咐 ffi 25347
内心 nxo 25231
暗中 vzi 23181其次,利用sbb空间。对于飞码和飞码X,利用的方式是不一样的。
对于飞码,在sbb上安排非强制性二字词简码,其取码规则为s1b1b1,SQL脚本如下。
select text=rtrim(zici), code=left(bianma,3)
from spciz
where xuhao in (
select xuhao from (
select bianma=left(bianma,3), xuhao=min(xuhao)
from spciz
where len(rtrim(zici)) = 2
group by left(bianma,3)
) tmp)一共抽取了451个二字词,罗列其中的前10条如下。
告诉 gue
声音 sei
眼睛 yia
一切 yee
改革 gae
朋友 pua
研究 yeu
代表 dui
不禁 beu
支持 zei对于飞码X,在为sbb空间安排二字词时,不能包含已经为其抽取的spb型二字词,脚本如下。
select zici = rtrim(zici), bianma = left(bianma,1) + substring(bianma,3,2),
chupin = case chupin when -1 then 0 else chupin end from sbjerz
where xuhao in (
select xuhao from
(select bianma = left(bianma,1) + substring(bianma,3,2), xuhao = min(xuhao) from sbjerz
where rtrim(zici) not in (
select zici from (
select zici = rtrim(zici), bianma = left(bianma,3),
chupin = case chupin when -1 then 0 else chupin end from sbjerz
where changdu = 3 and left(bianma,3) not in (
select bianma = left(a.bianma,3)
from spdanz a
right join sbjerz b on left(a.bianma,3) = left(b.bianma,3)
where a.changdu = 3 and b.changdu = 3)
) tmp)
group by left(bianma,1) + substring(bianma,3,2)) tmp2)一共抽取了525个s1b2b2型的二字词,罗列其中的前10条如下。
一个 yuo 997773
没有 meu 826617
我们 wui 812417
他们 tui 791018
什么 sua 742524
自己 zae 741012
知道 zou 574771
可以 kao 432546
这个 zuo 404217
就是 jia 376685快码(X)
首先,利用sy空闲空间。从声笔简码的二字词中抽出高频的填入该空间,脚本如下。
select zici = rtrim(zici), bianma = left(bianma,2), chupin = case chupin when -1 then 0 else chupin end from sbjerz
where changdu = 2 and left(bianma,2) not in (
select bianma = left(a.bianma,2)
from ybdanz a
right join sbjerz b on left(a.bianma,2) = left(b.bianma,2)
where a.changdu = 2 and b.changdu = 2)一共抽取了95个ss型的二字词,罗列其中的前10条如下。
可以 ky 432546
已经 yj 325164
发展 fz 323016
问题 wt 279209
一定 yd 201525
可能 kn 185841
今天 jt 173941
觉得 jd 172314
姑娘 gn 168226
一些 yx 165456第二,利用syb空闲空间。从声笔简码的二字词中抽出高频的填入该空间,脚本如下。
select zici = rtrim(zici), bianma = left(bianma,3), chupin = case chupin when -1 then 0 else chupin end from sbjerz
where changdu = 3 and left(bianma,3) not in (
select bianma = left(a.bianma,3)
from ybdanz a
right join sbjerz b on left(a.bianma,3) = left(b.bianma,3)
where a.changdu = 3 and b.changdu = 3)
order by chupin desc一共抽取了587个ssb型的二字词,罗列其中的前10条如下。
一个 ygu 997773
我们 wmu 812417
起来 qle 330495
还有 hye 191450
一点 ydi 189033
而且 vqi 176585
一下 yxe 167905
之间 zjo 139129
下来 xle 134533
眼睛 yji 133992第三,利用sbb空间。对于快码和快码X,利用的方式是不一样的。
对于快码,在sbb上安排非强制性二字词简码,其取码规则为s1b1b1,SQL脚本如下。
select text=rtrim(zici), code=left(bianma,3)
from ybciz
where xuhao in (
select xuhao from (
select bianma=left(bianma,3), xuhao=min(xuhao)
from ybciz
where len(rtrim(zici)) = 2
group by left(bianma,3)
) tmp)一共抽取了454个二字词,罗列其中的前10条如下。
经济 jaa
社会 soa
世界 sei
市场 soe
开始 kee
技术 jei
希望 xuo
表示 bee
改革 gae
国际 gia对于快码X,在为sbb空间安排二字词时,不能包含已经为其抽取的sy和syb型二字词,脚本如下。
select zici = rtrim(zici), bianma = left(bianma,1) + substring(bianma,3,2),
chupin = case chupin when -1 then 0 else chupin end from sbjerz
where xuhao in (
select xuhao from
(select bianma = left(bianma,1) + substring(bianma,3,2), xuhao = min(xuhao) from sbjerz
where rtrim(zici) not in (
select zici from (
select zici = rtrim(zici), bianma = left(bianma,2),
chupin = case chupin when -1 then 0 else chupin end from sbjerz
where changdu = 2 and left(bianma,2) not in (
select bianma = left(a.bianma,2)
from ybdanz a
right join sbjerz b on left(a.bianma,2) = left(b.bianma,2)
where a.changdu = 2 and b.changdu = 2)
union
select zici = rtrim(zici), bianma = left(bianma,3),
chupin = case chupin when -1 then 0 else chupin end from sbjerz
where changdu = 3 and left(bianma,3) not in (
select bianma = left(a.bianma,3)
from ybdanz a
right join sbjerz b on left(a.bianma,3) = left(b.bianma,3)
where a.changdu = 3 and b.changdu = 3)
) tmp)
group by left(bianma,1) + substring(bianma,3,2)) tmp2)一共抽取了525个s1b2b2型的二字词,罗列其中的前10条如下。
没有 meu 826617
他们 tui 791018
什么 sua 742524
自己 zae 741012
知道 zou 574771
这个 zuo 404217
就是 jia 376685
中国 zia 336314
这样 zei 328523
因为 you 317518公共
无论是飞码(X)还是快码(X),都还要利用sbbbx空间。将sbbb空间用于声笔单字输入,只有1、2级强制简码,重码字用aeiou来选择。声笔单字供用户在不知道偏旁部首或韵母时使用。‸
对于非X型的,脚本如下:
select zici = rtrim(zici), bianma = left(bianma,changdu),
chupin, stem = left(bianma,4) + upper(left(bianma,1))
from sbdanz where changdu <= 2
union
select zici = rtrim(zici), bianma = left(bianma,4),
chupin = case chupin when -1 then 0 else chupin end,
stem = left(bianma,4) + upper(left(bianma,1))
from sbdanz where changdu > 2
order by chupin desc对于X型的,由于正码的单字码表中已经包含了1、2级简码,并且不再需要构词码,所以脚本如下:
select zici = rtrim(zici), bianma = left(bianma,4),
chupin = case chupin when -1 then 0 else chupin end
from sbdanz where changdu > 2105个sb简码字的提示
制作一个滤镜供飞码(X)和快码(X)使用,包括sb105.txt和sb105.json,放在Rime的OpenCC子文件夹中。
sb105.txt的内容如下:
不  边a 把e 别i 部o 白u 
出  除a 成e 此i 次o 从u 
的  对a 大e 当i 道o 得u 
发  飞a 夫e 非i 方o 分u 
个  给a 过e 国i 高o 公u 
和  好a 还e 回i 话o 会u 
就  经a 进e 见i 家o 几u 
可  孔a 开e 口i 快o 看u 
了  力a 来e 里i 立o 利u 
们  民a 面e 明i 没o 么u 
你  那a 南e 内i 农o 年u 
平  皮a 破e 品i 怕o 片u 
去  强a 起e 且i 前o 全u 
人  如a 若e 日i 让o 然u 
是  双a 事e 上i 说o 手u 
他  她a 天e 同i 头o 体u 
而  阿a 二e 暗i 安o 儿u 
我  维a 无e 晚i 为o 外u 
下  线a 想e 小i 心o 笑u 
一  也a 有e 眼i 意o 用u 
在  子a 正e 中i 着o 自u sb105.json的内容如下:
{
"name": "sb105",
"segmentation": {
"type": "mmseg",
"dict": {
"type": "text",
"file": "sb105.txt"
}
},
"conversion_chain": [{
"dict": {
"type": "text",
"file": "sb105.txt"
}
}]
}另外,再创建为飞码、飞码X、快码和快码X分别创建一个配置文件:sbfm.custom.yaml, sbfmx.custom.yaml, sbkm.custom.yaml和sbkmx.custom.yaml,放在Rime文件夹中。这个几个文件的内容完全一样,如下所示。
patch:
"switches/@next":
name: sb105
reset: 1 #初始状态,0关1开
"engine/filters/@next": simplifier@sb105
sb105:
opencc_config: sb105.json
option_name: sb105
show_in_comment: true #开启编码滤镜
comment_format: #编码滤镜正则处理
- "xform/<br>/\n/" #编码滤镜内容换行
- "xform/ / /" #编码滤镜内容显示空格
tags:
- abc
tips: char #none无注释,char单字注释,all全部注释完成以上步骤后,重新部署就可以生效。
在计算机上的声笔字提示效果如下:
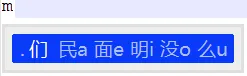
在手机上的声笔字提示效果效果如下:

实验结果
使用发现,开滤镜提示sb字后,导致一简字不能参与造词。还没有找到解决办法,只能暂时放弃滤镜。
结论
保留码表优化结果,暂时放弃用滤镜提示声笔字的功能。