Rime作为一款开源的输入法引擎,具有超强的定制能力,经过十几年的快速发展,现在已经形成了完整的生态,能支持各种类型的操作系统,还衍生出了很多特色鲜明的定制输入法,比如声笔系列码、雾凇拼音等等。
Rime还能使传统的字词型输入方案具有自动造词的能力,使得用户不必修改码表,甚至不必打开造词界面来输入编码,就可以通过你已经输入的字词来自动改造出更大的词组,快速地丰富用户词汇,从而加快输入速度。
但是,Rime的自动造词是通过枚举方式进行的,再加上因为同音字等而造成的一字多码,就可能出生大量用户用不着的废词。例如,在声笔飞码中,输入「声」「笔」「系」「列」「码」后,可能生成的词组为「声笔」「笔系」「系列」「列码」「声笔系」「笔系列」「系列码」「声笔系列」「笔系列码」「声笔系列码」。如果有同音字的话,每个词都可能产生多个编码。这些新造的词中,大部分都不是用户需要的,从而成为废词。这还是在最大造词长度设置为5的时候,如果设置为6或者更大,那么废词还会爆炸式地增长。
下面的两幅图是从声笔飞码的用户词典中导出的,充分说明了上述废词爆炸的情况。这个用户词典使用的时间并不长,总词条数多达26231条,其中正式的词组只有2471条,也就是说临时词组的数量高出正式词组将近10倍,而临时词组中的绝大部分永远也不可能成为正式词组,最终会变成废词。


废词太多的话,让有的用户看着不舒服,还占用了大量的空间,更重要的是会降低输入法的读写和检索速度,影响到用户的输入效率。
有没有办法对废词进行清理呢?办法肯定是有的,只是不同的方法,付出的成本或代价不一样。
最笨的办法是通过Rime的词典管理工具,将用户词典导出,然后手动删除那些不需要的临时词组(即废词)。这种方式工作量巨大,恐怕没有人愿意这么干。而且,在手机上没法进行这项工作。
另一种思路就是,开发一个工具来批量地删除废词。但是,以什么标准来确定一个临时词组是废词呢?首先想到的可能是时间。然而,人们使用输入法的频繁程度是不一样的。有的人一个月只有千字的输入量,而有的人一个月可能有上百万字的输入量,显然以时间作为标准是不适合的。
不过,这里提到的输入量是可以作为一个依据来删除废词的。怎么样才能知道用户的输入量呢?幸好,Rime记录了一个tick值,它会在用户每一次上屏输入内容都自动加1,用户词典还有个tick累计值。累计的tick值与词条的tick之差就反映了词条使用的频繁程度,该差值越小就说明词条使用越频繁,而差值越大就说明词条用得越少。


因此,可以将tick差值作为一个阈值来控制废词清理的强度,通过运行一个工具软件来删除那些大于此阈值的临时词组。这样就比导出用户词典来用编辑器逐个删除不需要的词条方便多了。美中不足之处是,工具的运行还是得手动进行。能不能再进一步,实现全自动的废词清理呢?能!此文的目的也就是讲如何实现全自动废词清理。然而,Rime现在是没有办法直接实现这一点的,需要修改其后端引擎librime的源代码才能实现。怎么修改?
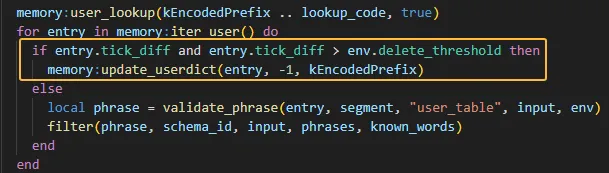
在user_dictionary.cc文件的LookupWords函数中针对某个输入编码查找匹配临时词组,若tick差值(present_tick - v.tick)大于某个阈值(threshold_),则将其删除。
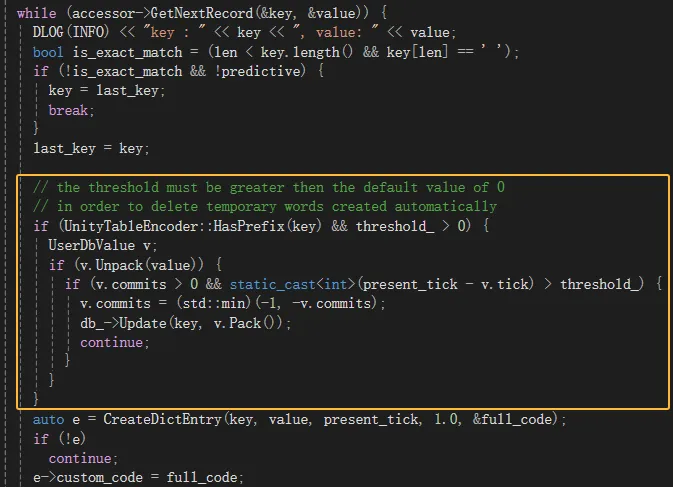
上述阈值可以在输入方案schema的translator项下用delete_threshold设置。
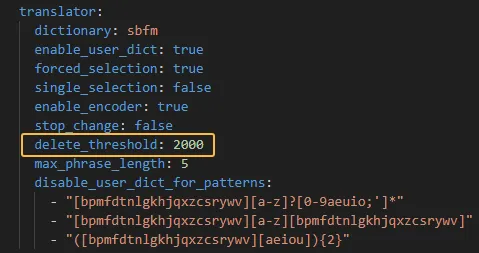
在TableTranslator的构造函数中会用schema中设置的阈值初始化成员变量delete_threshold_,并据此设置user_dictionary中的threshold_成员变量。
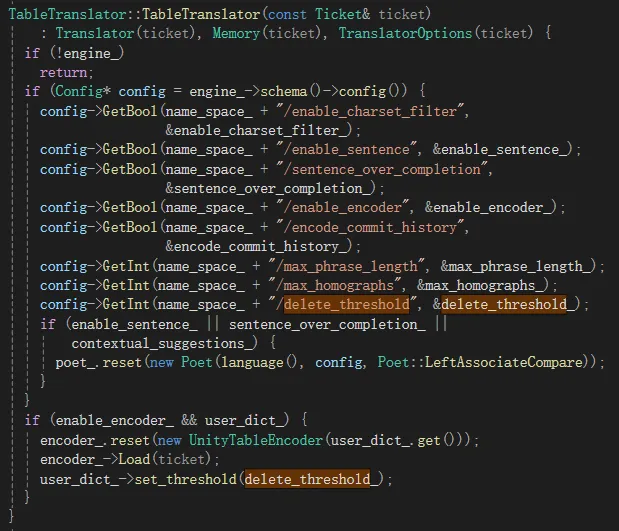
以上就是在为librime增加自动废词清理的办法,更具体的代码修改见此链接。但是,为了便于在librime-lua中插件中使用此功能,还需要再做些许改造。
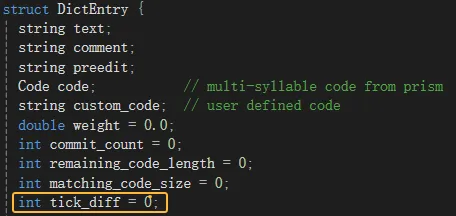
首先,在vocabulary.h头文件中,为DictEntry结构增加一个整型的成员tick_diff来表示词条的tick差值,并初始化为0。
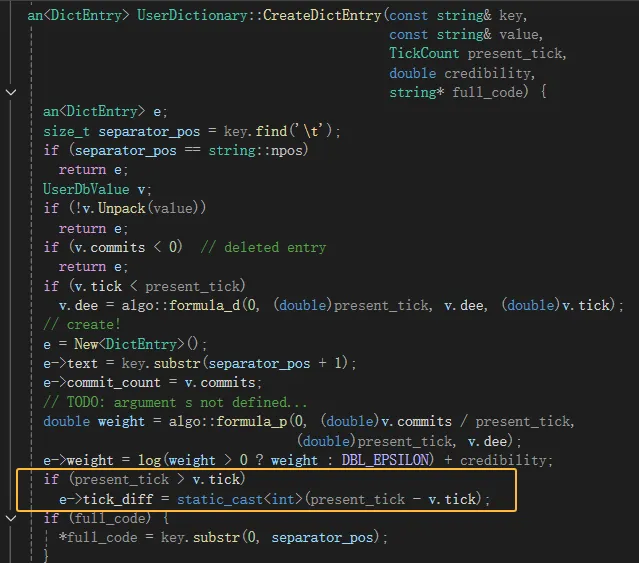
然后,在user_dictionary.cc文件中将它赋值给之前在DictEntry中新增的tick_diff成员。
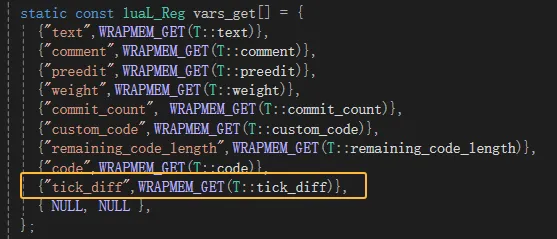
接下来,就是改造librime-lua插件,将types.cc中为DictEntryReg注册一个tick_diff变量,以便在lua脚本中使用就完事了。
最后,在lua脚本中就可以根据tick差值和删除阈值来进行废词的自动清理了。