1 引言
拼音输入法是中国大陆目前使用得最为广泛的输入方案,其用户比例至少在96%以上,甚至可能高达99%。确切地说,这里的拼音输入法是全拼输入,不包括双拼,因为后者使用的人非常少,相比全拼可以说是微乎其微。
在中国大陆,任何需要输入中文的设备或者操作系统,不论电脑、手机还是平板、电视,也不论Windows、MacOS、Android还是iOS,全拼输入方案都是必备的,而且是默认的中文输入方式。不管国际大公司如微软、谷歌、苹果,还是国内大厂如腾讯、百度、讯飞、华为,都推出了自己的拼音输入法。曾经那种万码奔腾的局面已经一去不复返了,大街小巷的五笔打字培训班也已经成为历史的记忆,自然码、两笔、郑码等其它原来比较知名的输入方案则越来越少为人知。笔画输入法也只有很少的人在使用,一般是功能机时代沿袭下来的。
为什么会形成全拼输入一家独大而其它输入方案几乎销声匿迹的现象呢?是全拼输入已经完美的解决了中文输入的问题,人们已经非常满意,别无他求了吗?拼音输入没有改进、优化的地方了吗?非也!而且远非如此!实际上,现在的拼音输入法还存在很多问题,有的问题可以说是怨声载道,有的问题是因为缺乏指导而使用不当造成的。
1.1 拼音输入问题
现在的拼音输入法常常被称为智能整句输入法。人们在描述输入法发展历史的时候,也常常说从字到词再到句。从理论上来说,更大的语境更有利于提高音字转换的正确性。从算法上来说,通过长期的积累,已经有成熟的隐马尔科夫模型和现代的大语言模型。从硬件上来说,CPU、内存、硬盘等性能大幅提升,价格大幅下降,已经不是问题。加上互联网的成熟,更可以利用大厂服务器的资源和大数据来提升智能整句输入法的能力。从用户的角度来说,使用整句输入可以没有分词的负担,还可以少按大量的空格,只需要练熟400来个音节拼式,只管一个劲地击键就行了。似乎一切都完美了!
然而,实际情况却让人大跌眼镜,绝大部分人并没有以整句为单位来输入,真正采用整句输入的人其输入的效率也并不高。整句输入的问题出在哪里?问题出在以下几个地方,即整句输入“八宗罪”。
(1) 编码效率低
拼音作为编码来说,编码效率太低,导致平均码长过长,超过了三码。汉语拼音的设计初衷是用于注音识读,所以遵循了音素化和国际化的原则。在这些原则的指导下,由于普通话自身的特点,使得拼音的字母利用效率很低,存在大量冗余。从编码的角度来说,用26个字母表达400个音节,每个音节只需要不到2个字母,因为26×26=676,可用的编码空间远远大于400,而汉语拼音却用了超过3个字母,所以效率会低。
(2) 确认成本高
整句的转换结果在输入的过程中可能会不断地发生变化,所以不到输入结束是不能判断其正误的,能够判断正误的只有输入的拼音串,拼音串不会发生变化。然而拼音并不是文字,人们对它的识读能力是很弱的,最多只能快速找出刚才输入的一两个音节的错误。因此,在输入过程中,最多只能做到输入的拼音串尽量不要出错。在一句话输入完成后,用户不通读一遍转换结果,是无法知道对错的,即使结果完全正确也需要进行确认,这一步还是少不了的,而且句子越长判别正误的成本越高。
(3) 键错概率大
人不是机器,人在输入编码时,击键的准确性是有限的,一般来说,在计算机标准键盘上,有95%的键准就不错了。如果在手机上操作,那么键准还会低不少。假设整句输入的平均长度为15个汉字,每字平均3键,平均每个句子用了45键,那么整句拼音键入完全正确的概率就只有0.95^45≈9.94%,不到10%!而且,随着句子长度的增加和击键速度的加快,正确率还会进一步下降。怎么办呢?现在的拼音输入法普遍都提供了自动纠错的能力。其原理是利用全拼的高冗余,对易于混淆的键进行容错。自动纠错确实能起到一些作用,但并非能完全纠正。同时,自动纠错还带来了新的问题,一是重码增多,二是可能会弄巧成拙,把用户本来需要的结果误改掉。
(4) 回改成本高
如果在上屏前确认时发现了错误,就需要进行回改。错误可能发生在一句话的任何位置,可能是转换结果有错,也可能是输入的拼音串有错。发现错误的位置后,需要先定位才能修改,其定位方法一般是用左箭头键逐个音节向前移动,用右箭头键逐个字母向后移动。箭头键的位置远离本位键,操作跨度大,缓慢、费时。搜狗拼音还有一个少用的方法是用Ctrl加字母键来定位,其特点是用键次数少,但是操作难度大,而且在手机上不适用。
(5) 残错概率大
不少人习惯于在输入过程中监视转换结果,在输入最后一个字词时就不再观察转换结果,然而可能正是这最后一个字词又导致前面已有的结果发生变化,导致错误。这种错误,用户往往不容易发现,使得残错率升高,因为他不自觉地会认为,前面是正确的,最后一个选择也正确的话,就不会有错了。另一种情况是,明明知道还有错误,但是因为觉得修改太麻烦了,就不愿意修改而直接上屏了;这在打字比赛之类的紧急场合和聊天之类的不严肃场合是很常见的。还有一种情况是,由于输入的内容很多,虽然仔细检查了,以为没错,但是实际上仍然还有没检查到的错误。
(6) 可重用性差
拼音输入法是以输入单位进行记忆的。以句子为单位进行输入,就是以句子为单位进行记忆。而句子,除非是很短的日常用句,在使用中重复的可能性是非常小的。这样,输入法就很难学习到用户的输入习惯,也就很难根据用户的输入习惯来改进输入效果。例如,前面的「也就很难根据用户的输入习惯来改进输入效果」这样一句话,很难被再次原封不动地使用。
(7) 自由度受限
为了提高转换的准确性,行文就不能太有创意,要尽量使用大众化的表达方式。用俗话来说,就是要尽量说口水话。你要说「检查错误的方法」而不要说「查错法」或者「检错法」。使用这种简略的说法,需要事先造词,然后才能用在句子当中。造词的过程并不简单,你得先以词为单位输入一遍,在句子中输入一遍是不能造出这个词的。可是,按词输入是整句模式的弱项,选重非常麻烦。更为伤脑筋的是,你常常并不知道系统中是否有某个词。
(8) 适应性不强
在不少时候,用户无法以句子为单位来进行输入。例如,在进行文章的审校时,往往是只是对个别的字词进行修改,这时不得不以字词为单位来输入。又如,在列出人名时,也只能以名字为单位进行输入,而不是句子。再如,打购物清单的时候,也只有逐个物品的输入。所以,整句输入适应性差,不能很好地适应各种应用场景,是不完备的输入方式。
有鉴于以上原因,拼音输入应该以字词为单位而不是以句子为单位。实际上,除了极少数死心塌地的整句派,大多数人也是这么做的。先进行正确的分词,然后按字词进行输入,可以在一定程度上同时克服以上问题。在输入字词时可以适时地使用简拼,从而缩短码长,提高编码效率。字词的长度一般不会超过四个字,确认和回改的成本会大大降低,错误更容易发现和修改,残错率也会减小。
1.2 拼音输入改进
通常,为了在拼音输入的时候克服以上问题,人们首先想到的可能就是采用双拼。但是,双拼的门槛还是不低,需要记住30来个韵母、3个翘舌声母和零声母的表示形式,而且仍然不能解决重码多的问题。同时,双拼能够节约的用键,被无法或者难以使用简拼的缺点部分抵消掉了。
声笔拼音则另辟蹊径,以全拼为基础,进行适当的变形,不分平翘舌,不区分前后鼻音,只需花费比双拼小得多的代价,就可以取得相当于甚至高于双拼的输入效率。声笔拼音是一种非常「奇特」的拼音输入法,它完全颠覆了人们对拼音输入法的认识,平均码长和重码大幅度减少,翻页键很少用得着,输入效率大大提升。
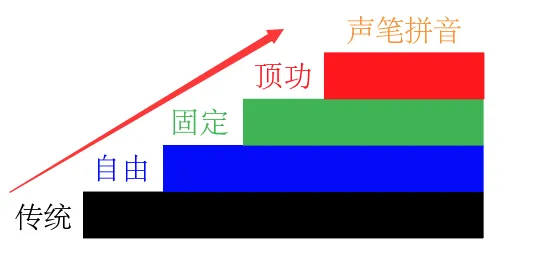
声笔拼音三板斧,在传统拼音基础上实现三次大飞跃
- 自由编码:缩短和变换拼式、直辅笔画
- 固定简码:截断固定、数选固定
- 顶功省键:优化路径、省略空格、快速回改
1.3 适用人群
声笔拼音适合什么样的人使用呢?声笔拼音是对现有拼音输入法的优化和改进,所以它适用于正在用拼音输入中文的所有人,可以仅花费极小的代价就获得高得多的中文输入效率,而不必花更多的时间和精力去学习双拼甚至五笔等。声笔拼音将彻底改变人们对拼音输入时重码多、效率低的刻板印象,是最佳的拼音输入法升级方案。
如果您的拼音非常糟糕,对不分前后鼻音的韵母都掌握不了,同时又想有一个简单高效的输入方案,那么强烈建议您使用声笔系列码中的声笔简拼,它仅使用不分平翘舌的声母和五个笔画,在不用韵母的情况下,就能取得比声笔拼音还高的输入效率。
1.4 内容介绍
本文只涉及声笔系列码中的声笔拼音。有关声笔系列码的总体情况请参见总体介绍。有关下载、安装和配置的方法,请参见安装配置。有关声笔系列码的发展历史,请参见发展历程。对于一些常见问题的解答,请参见常见问题。声笔系列码的其它输入方案详见各自的专题。
2 快速入门
2.1 编码规则
声笔拼音的编码元素为声母、韵母和笔画,具体表示方法与现行拼音输入法有一定的差异,请注意以下几点。
- 冠零声:用v表示零声母,即作为以
a e o开头的音节在形式上的声母。例如,ai ei ou就变成了vai vei vou。 - 去翘舌:不区分平、翘舌音,即省略
zh ch sh中的h。例如,zhou chao shi就变成了zou cao si。 - 省介音:在声韵相拼的时候,声母
j q x后接以ia ie io开头的韵母如ia ie iao ian iang iong时,要省略i。例如,传统拼音里的jie qiong xiang在声笔拼音里则变成je qon xan。 - 截韵尾:音节长度超过3时,则截断为3。例如,
biao变成bia,而guan变成gua。这也导致了不区分前后鼻音,即省略ng中的g。例如,bang zong就变成了ban zon。 - 去鼻音:将末尾的n置换成其前面的元音字母。例如,
bin变成bii,而xan变成xaa。 - 调手感:为韵母aa增加手感兼容码au,以减少左手小指连击。例如,
qaa也可用qau。 - 理特例:将韵母
er合并到e,ü合并到u,ê合并到e。例如,er变成ve,nü变成nu,而ê变成ve。特别注意,ü没有像传统拼音输入法那样用v来代替。 - 纯音节:对,两字母的音节,在不知道笔画时,可用
'作为第三码来占位。例如,li变成li',wo变成wo'。 - 补笔画:补充笔画直至码长为9,笔画不够时重复末笔;横竖撇捺折五个笔画用
eiuoa来表示。例如,「笔」的拼音为bi,追加前七个笔画后编码为biueoueou。又如,「将」的音节为jaa,追加前六个笔画后的编码为jaaoeiuao。再如,「乙」的音节为yi,而「乙」只有一个笔画,所以要重复六次才能形成编码yiaaaaaaa。需要注意的是,在实际输入的时候,一般是不用9位全码的。
通过以上简单的改造,就可以取得以下奇特的效果。
- 拼写形式得到了缩短,例如:
zhuang变成了zua,miao变成了mia。 - 可以直接追加笔画进行快速筛选,例如:
依yiu 衣yio 议yioa 艺yie。虽然现有拼音输入法也可以用Tab来引导加笔画,但是只能作用于单字和词组中的首字,而且增加了码长。 - 音节之间界线完全明确,在连续拼写的时候根本不需要使用隔音符来排除切分歧义,例如:
xi'anshi变成了xivaasi或者xivausi。虽然现有拼音输入法也可以用单引号来隔音,但是增加了码长,同时也容易忘记使用。 - 降低了学习门槛,不再需要区分平翘舌和前后鼻音。虽然现有拼音输入法也可以设置模糊音,但是会影响汉字转换的准确性,而在声笔拼音中不会有这个问题,因为声笔拼音中不再保留翘舌音和后鼻音的拼式。
下面我们通过一些例子来熟悉一下上述7条编码规则。对于每个字,依次运用这些规则就是了。当然,在熟悉以后,是不必每个规则都去用一下的,因为直觉会告诉你哪个或者哪些规则是适用的。
- 声sheng:不是零声母音,不适用规则1;用规则2去除翘舌后,拼式变成seng;没有介音,不适用规则3;用规则4截去韵尾后,拼式变成sen;用规则5去掉鼻音后,拼式变成see;不是特例,不适用规则6;用规则7补充笔画后,拼式变成seeeieaie。
- 将jiang:不是零声母音,不适用规则1;不是翘舌音,不适用规则2;用规则3去掉介音后,拼式变成jang;用规则4截去韵尾后,拼式变成jan;用规则5去掉鼻音后,拼式变成jaa;用规则6为jaa增加jau兼容码;不是特例,不适用规则7;用规则8补充笔画后,拼式变成jaaoeiuao或jauoeiuao。
- 快kuai:不是零声母音,不适用规则1;不是翘舌音,不适用规则2;没有介音,不适用规则3;用规则4截去韵尾后,拼式变成kua;没鼻音,不适用规则5;韵母不是aa不适用规则6;不是特例,不适用规则7;用规则8补充笔画后,拼式变成kuaooiaeu。
- 儿er:用规则1添加零声母后,拼式变成ver;规则2、3、4、5、6都不适用;用规则7后,拼式变成ve;用规则8后,拼式变成veuaaaaaa。
- 虐nüe:规则1、2、3、4、5、6都不适用;用规则7后,拼式变成nue;用规则8后,拼式变成nueieauea。
- 创chuang:用规则1后,拼式变成cuang;用规则4后,拼式变成cua;用规则8后,拼式变成cuauoaaii。
2.2 助记方法
虽然声笔拼音已经简单,基本上没有什么学习门槛,但是为了进一步减轻初学者的记忆负担,在手机上提供了助记皮肤,可以长按N键打开或者关闭助记。在打开时,给出了笔画和零声母用键(aeuio和v)的提示,如下图所示。如果是在电脑上,则可以把该图放在电脑桌面上,在打字的时候帮助记忆,一般几分钟就记住了。

2.3 反查方法
在使用声笔拼音时,特别是在学习声笔拼音之初,有时会遇到不会打的字。怎么办呢?声笔程序提供了丰富的反查手段,可以通过笔画和一般拼音来反查编码,还可以采用字海两分来反查和输入非 GBK 汉字。注意,虽然在反查的结果中只显示了六位单字编码,但是实际输入的时候是可以用九位的,也就是可以再追加三个笔画。
2.3.1 拼音反查
在知道一般拼音而不知道字形时用 a 引导拼音反查。
例如,要反查「防」字的编码,就在输入 a 之后再输入它的拼音fang,所以实际的输入为 afang,结果如下图所示。反查出「防」字的编码为 faaaio。如果是多音字,那么就会有多个编码,如图中的「房」字就有 faaoae 和paaoae 两个编码。由于aa可优化手感为au,所以反查时只显示了后者,以免拥挤。

对于零声母字,如「案」字,在反查时除了用a 引导还需要在正常拼音的前面加 v,因为 an 是零声母音,所以实际的输入为 avan。在下图中提示出的案vaaooa,表示「案」字的编码为 vaaooa。由于aa可优化手感为au,所以反查时只显示了后者,以免拥挤。

2.3.2 笔画反查
在完全不知道读音的时候,直接用 aeuio 按顺序输入笔画进行反查,无需引导。
在下面的笔画反查的例子中,不用引导而直接输入 uuao 后,出现了以这四个笔画开头的字。第一项是反faauua,表示「反」字的编码为 faauua。第二项为般baauua pouuao paauua,说明「般」是个多音字,有三个编码。由于aa可优化手感为au,所以反查时只显示了后者,以免拥挤。

2.3.3 两分反查
通过 i 引导的拼音还支持用字海两分法来进行反查, 支持查找八万多汉字,一般用于反查难读而易于两分的字或者输入 GBK 以外的字。GBK 以外的字,声笔拼音不提供正常编码,不能按正常方式输入,只能在两分查找到后选择输入。引导字母i可以理解为英文inquire(询问)的首字母,以便记忆
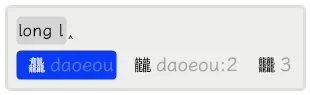
下面是字海两分法查找的例子。第一个例子是反查「龖」字的编码,在输入到第二部分拼音的第一码时就出来了。第二个例子是通过输入「尸」和「水」的拼音来反查「尿」的编码,输入了两部分完整的拼音。

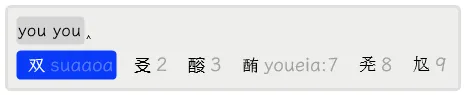
对于非 GBK 字集里的「㕛」字,它是没有编码的,只能用两分法来输入,如下所示。
2.4 基本输入
Tab和Shift Tab分别用于向前和向后翻页。Esc用于清除所有编码,退格键用于删除光标前的一个编码。首选项用空格上屏,不过常常可以省略。重码项用23789上屏,而不是传统的123456,这样更便于操作,而且23789有时候是与笔画对应的。
为了避免歧义和便于记忆,我们将用下列类似正则表达式的精简方式来描述顶功模式下字词的输入格式。其中,s = [qwrtsdfgzxcvbyphjklnm]表示声母,b = [aeuio]表示笔画,y[aeuio']表示韵母中的字母或者分隔符),*表示按笔顺取零个或者多个。括号里的为补码,补码在实际输入时是补在编码最后而被自动提前的。大写的S表示声母需要用大写字母。
单字:
sb, syyb*6二字词:
s(yyb*6)syy三字词:
s(yy)s(yy)syy四字词:
s(yy)s(yy)s(yy)syy五字及以上的词:
s(yy)s(yy)sS*(yy)syy
可以看出,笔画在输入过程中并不是绝对需要的,但是笔画对单字和二字词的重码离散有着非常重要的作用,解决了纯拼音输入的最大痛点。
另外要注意,三字词、四字词和多字词每个字只能输入三码,而单字和二字词的首字可以输入九码。这是为了解决单字和二字词编码空间狭小而不能满足充分离散重码的问题而做的特殊设计。
3 输入例解
3.1 单字的输入
单字的顶屏能力很强,从第二码就开始顶了,也就是说只有一简字需要空格上屏,其它首选字都可以省略空格。
3.1.1 实例一
「我」是一简字,只需要声母w,要加空格上屏。

3.1.2 实例二
「给」是二简字,只需要声母g和首笔a(相当于输入格式中的sb)即可。如果后续其它字词如「你」的声母n,那么,「给」就会被顶上屏幕,从而节约空格键。

当然,采用声韵来输入「给」也是可以的。这时,会提示出该字的声笔码,以便用户采用。

3.1.3 实例三
「喜」不属于一、二简字,在输入了xi后,读音就输完了,所以第三码用单引号补足。这时,假设「喜」出现在首选了,那么就可被顶了。当然,因为调频的原因,xi'上的首选字有可能不是「喜」,但毫不影响理解这里说的顶屏。

当然,在xi后直接追加笔画也是可以的。不过需要注意,在省略分隔符直接加笔画时,一个字的最大码长只有4而不是9。

3.1.4 实例四
「素」字,假设在输入su'ee后出现在首选了,从而可以被顶。因为调频位在第三位上,下次再输入「素」字就很可能只需要su'三码了。

直接追加笔画时,可以节约一码。

如果只使用纯音来输入,那么需要翻页一次,然后选择重码。


3.1.5 实例五
在同音字很多的时候,很可能就需要输入七码甚至更多码,才能出现在首位。


3.2 二字词输入
3.2.1 实例一
「我们」一词,输入两码后就出现在首选了,这时一般需要空格上屏,除非是后续标点符号。

3.2.2 实例二
「外贸」一词,输入三码后,就出现在首选了,可以顶屏,如下所示。

注意,声笔拼音在输入的时候,不需要输入完整的拼音,而是通过前缀进行匹配的,这样可以尽量缩短码长,提高输入效率。
3.2.3 实例三
「干洗」一词,在输入至少三码以后,并进行补码,只要「干洗」出现在首位,就可以顶屏。

觉得用gaa手感不好,可改用gau。

对于这个词,直接在xi后加笔画的效率更高,但是就不是纯音输入了。

3.3 三字词输入
3.3.1 实例一
「计算机」一词,输入jsji后,该词已是首选,处于顶屏位,也可以被顶。

3.3.2 实例二
「脚手架」一词,输入jsja后,并没有出现在首选,可以数选上屏,也可以继续输入末字的编码。


这里的jaa也可改用jau,以改善手感。

想要的词还没有出现在首选,可以进行补码,输入首字的韵母首字母后,「脚手架」就到首选了。

3.3.3 实例三
如果「击键率」一词,在末字输入了三码后,情况如下。

由于候选项中没有「击键率」,于是补充首字的编码。

发现已经没有三字词,开始出现二字词了,「击键」出现在候选项里了,用2选中它。

「率」字没有出现,补充其首笔,发现它已经到了首选,空格上屏完成输入,并造好了「击键率」这个词。

3.4 四字词输入
3.4.1 实例一
「红光满面」一词,输入四码就是首选了,可以顶屏。

3.4.2 实例二
要输入「永生永世」,输入四码ysys,并没有出现首页。

此时可以翻页查找。

更好的办法是继续输入末字的第二码i,即「世」的韵母,该词出现在候选项中,此时可以选择上屏。

也可以在末字输入完三码后,补充首字编码,直到「永生永世」便成为首选,以便顶屏。

3.4.3 实例三
假设现在要输入「声笔系列」,发现在输入sbxl后,情况如下。

没有发现该词,于是继续追加末字两码。

还没有发现该词,于是回头追加首字韵母。

仍然没有发现该词,于是继续追加第二字韵母。


系统组合出了「声笔系列」这个词,完美!
3.5 多字词输入
五字及以上的词称为多字词。
3.5.1 实例一
「床前明月光」,在输入完四码后,由于有长词联想功能,它可能会已经出现在候选项中。

如果想将它提前到首选,只需要大写输入第五字声母即可,注意提示的编码仍然是小写的。

3.5.2 实例二
假设现在要输入「声笔系列码」,其过程如下。



此时,用4定位到第二音节之后,以便输入「声笔」。


继续为剩余的部分补码,出现了「系列」。

用3选择「系列」后,提示如下。

此时,如果后面还要输入「是」字,那么输入s就会将「声笔系列码」顶上屏幕,并造好该词。 整个造词过程犹如行云流水,与常规的输入过程几乎是合而为一了。
3.5.3 实例三
如果已知某个五字及以上的长词在系统中没有而需要新造,那么采用输入首码后按Shift+Tab(手机是上滑Tab)进入缓冲模式来造词是最好的,这时只需要拆开后输入一遍这个长词即可,而不必先输入所有的声母再回头补码。
例如,要输入「顶功输入高手」,缓冲造词的情况如下。



这时空格并不会上屏,而是会停留在缓冲区中。

需要再次空格才能上屏,同时退出缓冲模式,当然也造好了这个长词。再次输入的时候,只需要前四码就会因为长词联想而出现在候选项中。

4 数标固定
除了一、二简字词外,声笔拼音还有大量固定的数选字词以及少量标点字词,包括210个声数字、42个声标字、210个声笔标字和4410个声声数词,它们有助于提高声笔拼音的可盲打性,从而提高输入效率。固定字词分为有理的和无理的两组,默认情况下只提示有理组,可以设置为同时提示无理组,以下示例是设置为同时提示无理组的情况。有理组用23789代表折横撇竖捺,而无理组用;'14560进行选择,与笔画无关。
例如,在输入z后,如果直接输入;'14560将顺序选择「最 种 展 之 作 主 则」几个字。

又如,在输入zy后,如果直接输入14560将顺序选择「怎样 重要 只要 主要 终于」五个词。其中,1可以换用单引号,而0可以换用Tab。

5 自定词典
声笔拼音的所有固定字词,包括一简字、声笔字、声声词等,以及所有固定的数选字词,都是可以修改定制的,它们位于sbpy.fixed.txt文件中。您修改保存后,重新部署一下就可以生效。
6 组合固定
在输入三个声母时,首选项会变成二简词和一简字的固定组合,只有输入末字的第二码,才会开始检索三字词,从而可以在不增加用键的情况下减少人机交互,提高输入效率。


7 组合变换
组合变换操作用于输入一二简字、二简词之间的组合,熟悉后可以盲打,还可以用来规避重码。表达式中的_表示空格。
两个一简字的组合:
ss; => s_s_,例如「就是js;」「一个yg;」「是的sd;」等等。一简字与二简词的组合:
sss; => s_ss_,例如「是为了swl;」「的时候dsh;」等等。一简字与二简字的组合:
ssb; => s_sb_,例如「就为jwo;」「的事dse;」。因为sb的空格可以省略,所以并不一定节约用键,但可避免在输入错误时发生回改。二简词与一简字的组合:
sssTab => ss_s_,适用于非fix_combination模式,因为在fix_combination模式,用空格上屏就行了。三个一简字的组合:
sss' => s_s_s_,其中的单引号也可以换用Shift+空格,例如「一个人ygr'」「就是了jsl'」等等。两个二简词的组合:
ssss; => ss_ss_,例如「经济文化jjwh;」「建设服务jsfw;」等等。二简词与二简字的组合:
sssb; => ss_sb_,例如「经济上jjsi;」「地方有dfye;」等等。二简词与两个一简字的组合:
ssss'=>ss_s_s_,其中的单引号也可以换用Shift+空格,例如「我们就是wmjs'」「他们不是tmbs'」等等。
8 长词联想
如果Rime的前端支持1.11.0及以上的librime,而且未将translator的enable_completion设为false时,那么在输入四个声母后就可以进行长词联想。这样,在输入长词时就不必输入完所有的声母即可进行选择了。
例如,在输入zhrm后,也会同时检索出因此为前缀的长词,如下所示。

同理,输入zhrmg后,会联想出更长的词组。
